Instantly download Associate-Developer-Apache-Spark-3.5 training test engine

Pass4training offer you the best valid and useful Databricks Associate-Developer-Apache-Spark-3.5 training material
Last Updated: May 31, 2026
No. of Questions: 135 Questions & Answers with Testing Engine
Download Limit: Unlimited
Complete & valid Associate-Developer-Apache-Spark-3.5 training questions for 100% pass!
Pass4training has a strong professional team who are devoting to the research and edition of the Associate-Developer-Apache-Spark-3.5 training test, thus the high quality and validity of Associate-Developer-Apache-Spark-3.5 torrent pdf can be guaranteed.You can easily pass the actual test with Associate-Developer-Apache-Spark-3.5 study material.
100% Money Back Guarantee
Pass4training has an unprecedented 99.6% first time pass rate among our customers.  We're so confident of our products that we provide no hassle product exchange.
We're so confident of our products that we provide no hassle product exchange.
- Best exam practice material
- Three formats are optional
- 10 years of excellence
- 365 Days Free Updates
- Learn anywhere, anytime
- 100% Safe shopping experience
- Instant Download: Our system will send you the products you purchase in mailbox in a minute after payment. (If not received within 12 hours, please contact us. Note: don't forget to check your spam.)
Databricks Associate-Developer-Apache-Spark-3.5 Practice Q&A's

- Printable Associate-Developer-Apache-Spark-3.5 PDF Format
- Prepared by Associate-Developer-Apache-Spark-3.5 Experts
- Instant Access to Download
- Study Anywhere, Anytime
- 365 Days Free Updates
- Free Associate-Developer-Apache-Spark-3.5 PDF Demo Available
- Download Q&A's Demo
Databricks Associate-Developer-Apache-Spark-3.5 Online Engine

- Online Tool, Convenient, easy to study.
- Instant Online Access
- Supports All Web Browsers
- Practice Online Anytime
- Test History and Performance Review
- Supports Windows / Mac / Android / iOS, etc.
- Try Online Engine Demo
Databricks Associate-Developer-Apache-Spark-3.5 Self Test Engine

- Installable Software Application
- Simulates Real Exam Environment
- Builds Associate-Developer-Apache-Spark-3.5 Exam Confidence
- Supports MS Operating System
- Two Modes For Practice
- Practice Offline Anytime
- Software Screenshots
Reliable products
It is undeniable that Associate-Developer-Apache-Spark-3.5 pdf trainings have a bearing on the results of exam outcomes. With the help of best materials your grade will be guaranteed. However, with so many materials flooded into market in recent years, the indiscriminate choose means greater risks of failure, so the content of materials should not be indiscriminate collection of information but elaborate arrangement and compile of proficient knowledge designed for Associate-Developer-Apache-Spark-3.5 study torrent, so please trust us without tentativeness.
Dear friend, it is a prevalent situation where one who holds higher level of certificates has much more competition that the other who has not. Therefore, it is an impartial society where one who masters the skill will stand out. Our Associate-Developer-Apache-Spark-3.5 practice materials have evolved in recent years and have gained tremendous reputation and support by clients around the world.
Besides, it is in a golden age of you to pursuit your dreams and it is never too much to master more knowledge to strengthen your ability, which is also of great help to being competent compared with others. To qualify yourself to become outstanding elite in your working area, you need a lot of help from different people. And it is essential to meet relevant requirements of company with necessary Associate-Developer-Apache-Spark-3.5 professional credentials, or academic objectives successfully. We are here to introduce our Databricks Certification Associate-Developer-Apache-Spark-3.5 exam questions for you. Let us take a succinct look together.
Outstanding services as our duty
The company staff is all responsible and patient to your questions for they have gone through strict training before go to work in reality. So they are waiting for your requires about Associate-Developer-Apache-Spark-3.5 : Databricks Certified Associate Developer for Apache Spark 3.5 - Python pdf cram 24/7. Besides, our staff treasures all your constructive opinions and recommends, we can be better our services in all respects. We acknowledge any kinds of forthright comments if you hold during using process. So with the excellent Associate-Developer-Apache-Spark-3.5 valid torrent and the outstanding aftersales services, we gain remarkable reputation among the market by focusing on clients' needs.
Numerous customers attracted by our products
By using our Associate-Developer-Apache-Spark-3.5 prep material, a bunch of users passed the Associate-Developer-Apache-Spark-3.5 actual exam with satisfying results--- high score and gain certificates finally. And we still quicken our pace to make the Databricks Associate-Developer-Apache-Spark-3.5 latest pdf more accurate and professional for your reference. The formers users have built absolute trust who bought them already before, and we believe you can be one of them. The total number of the clients is still increasing in recent years. By using our Associate-Developer-Apache-Spark-3.5 practice materials, they absorbed in the concrete knowledge and assimilate useful information with the help of our products to deal with the exam easily, and naturally, we gain so many faithful clients eventually.
Professional Associate-Developer-Apache-Spark-3.5 practice materials come from specialists
We have a group of experts who devoted themselves to Associate-Developer-Apache-Spark-3.5 practice vce research over ten years and they have been focused on proficiency and accuracy of Associate-Developer-Apache-Spark-3.5 latest vce according to the trend of the time closely. All the necessary points have been mentioned in our Databricks Certification Associate-Developer-Apache-Spark-3.5 practice materials particularly. About some tough questions which are hard to understand or important knowledges that are easily being tested in exam. Therefore, our products are the accumulation of professional knowledge worthy practicing and remembering. The specialists paid painstaking effort as some irreplaceable adepts in their career and can be trusted with confidence.
Databricks Certified Associate Developer for Apache Spark 3.5 - Python Sample Questions:
1. 47 of 55.
A data engineer has written the following code to join two DataFrames df1 and df2:
df1 = spark.read.csv("sales_data.csv")
df2 = spark.read.csv("product_data.csv")
df_joined = df1.join(df2, df1.product_id == df2.product_id)
The DataFrame df1 contains ~10 GB of sales data, and df2 contains ~8 MB of product data.
Which join strategy will Spark use?
A) Shuffle join because no broadcast hints were provided.
B) Shuffle join, as the size difference between df1 and df2 is too large for a broadcast join to work efficiently.
C) Broadcast join, as df2 is smaller than the default broadcast threshold.
D) Shuffle join, because AQE is not enabled, and Spark uses a static query plan.
2. 3 of 55. A data engineer observes that the upstream streaming source feeds the event table frequently and sends duplicate records. Upon analyzing the current production table, the data engineer found that the time difference in the event_timestamp column of the duplicate records is, at most, 30 minutes.
To remove the duplicates, the engineer adds the code:
df = df.withWatermark("event_timestamp", "30 minutes")
What is the result?
A) It is not able to handle deduplication in this scenario.
B) It accepts watermarks in seconds and the code results in an error.
C) It removes all duplicates regardless of when they arrive.
D) It removes duplicates that arrive within the 30-minute window specified by the watermark.
3. 35 of 55.
A data engineer is building a Structured Streaming pipeline and wants it to recover from failures or intentional shutdowns by continuing where it left off.
How can this be achieved?
A) By configuring the option checkpointLocation during readStream.
B) By configuring the option checkpointLocation during writeStream.
C) By configuring the option recoveryLocation during writeStream.
D) By configuring the option recoveryLocation during SparkSession initialization.
4. An MLOps engineer is building a Pandas UDF that applies a language model that translates English strings into Spanish. The initial code is loading the model on every call to the UDF, which is hurting the performance of the data pipeline.
The initial code is:
def in_spanish_inner(df: pd.Series) -> pd.Series:
model = get_translation_model(target_lang='es')
return df.apply(model)
in_spanish = sf.pandas_udf(in_spanish_inner, StringType())
How can the MLOps engineer change this code to reduce how many times the language model is loaded?
A) Convert the Pandas UDF from a Series → Series UDF to an Iterator[Series] → Iterator[Series] UDF
B) Convert the Pandas UDF from a Series → Series UDF to a Series → Scalar UDF
C) Convert the Pandas UDF to a PySpark UDF
D) Run the in_spanish_inner() function in a mapInPandas() function call
5. A data engineer is working on the DataFrame: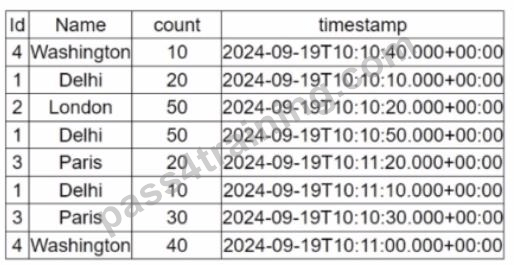
(Referring to the table image: it has columns Id, Name, count, and timestamp.) Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
A) df.select("Name").distinct()
B) df.select("Name").distinct().orderBy(df["Name"].desc())
C) df.select("Name").orderBy(df["Name"].asc())
D) df.select("Name").distinct().orderBy(df["Name"])
Solutions:
| Question # 1 Answer: C | Question # 2 Answer: D | Question # 3 Answer: B | Question # 4 Answer: A | Question # 5 Answer: D |
 Marina
Marina
Ophelia
Shirley
Xaviera
Armstrong
Borg
Pass4training is the world's largest certification preparation company with 99.6% Pass Rate History from 67295+ Satisfied Customers in 148 Countries.

Over 67295+ Satisfied Customers

Our Clients

We are the reliable training platform to offer you the latest and valid practice material for the actual test. The high quality and high pass rate is the guarantee of success.
Contact Us
From Monday to Saturday
Support: Contact now
If you have any question please leave me your email address, we will reply and send email to you in 12 hours.
Copyright © 2026 PASS4TRAINING.COM. All rights reserved. All trademarks are the property of their respective owners and we don't provide actual questions from any vendor. Privacy Policy